
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- restful
- selenium
- springboot 크롤링
- mcpserver
- 개발자튜토리얼
- 스프링부트
- 자바스크립트기초
- rest api
- 브랜치관리전략
- spring
- 모던 자바스크립트
- 회원관리
- CRUD
- Github action
- modelcontextprotocol
- 깃허브
- CI/CD
- llm연동
- 백엔드개발
- SQLD
- 깃플로우
- mcp
- springboot크롤링
- github
- Nan
- 네이버 크롤링
- SpringBoot
- springframework
- 자바스크립트
- gitflow
Archives
- Today
- Total
JUNEee
[Spring Boot] selenium 을 사용한 네이버 플레이스 리뷰 크롤링(1) 본문
반응형
- 결과 화면
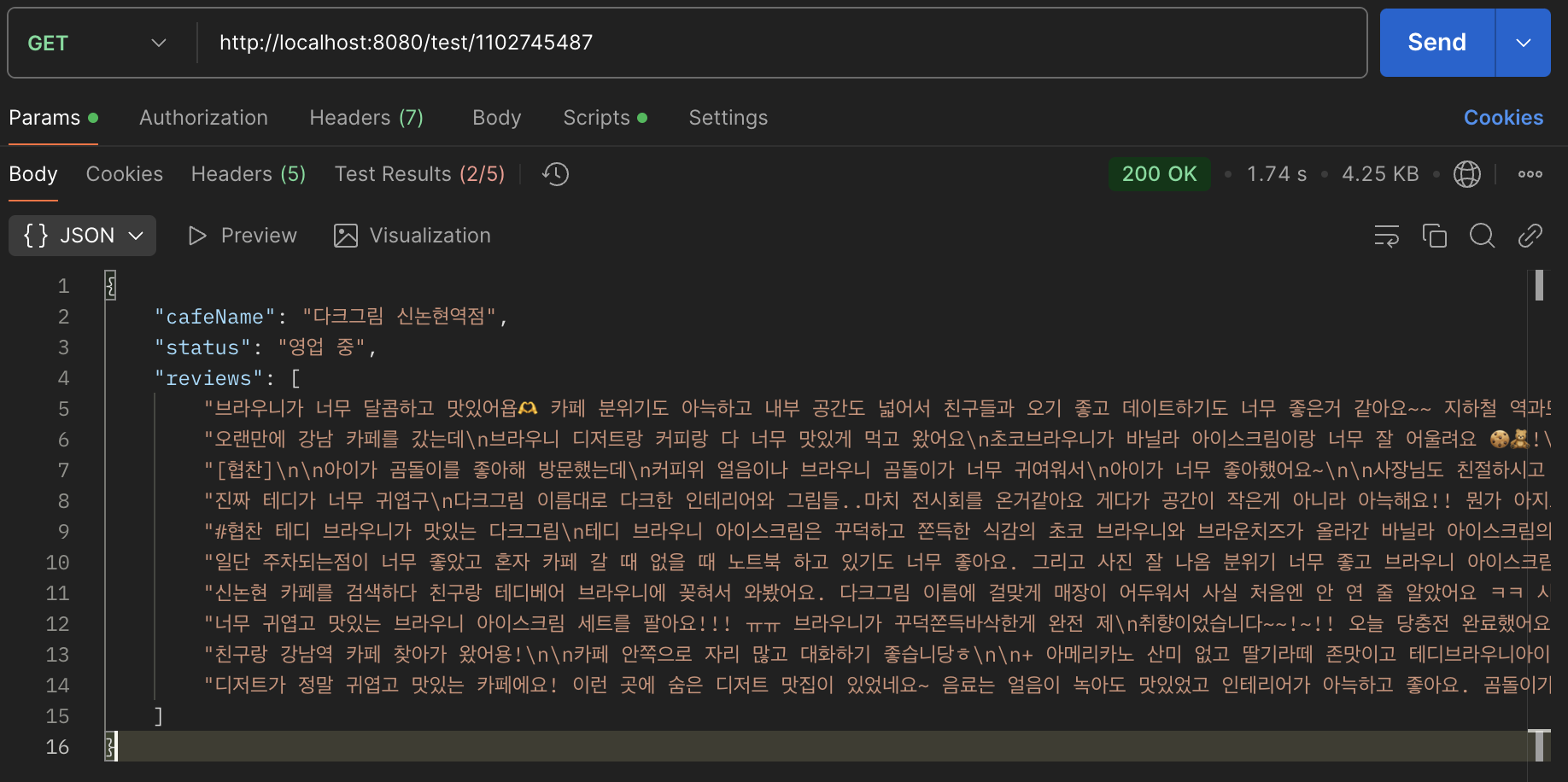
최종적으로 완성된 화면이다.
제목은 '리뷰 크롤링' 이라고 지었으나, 리뷰 뿐만 아니라 영업시간과 영업중인지 아닌지 등 대부분의 데이터 들을 크롤링 하여 활용할 수 있다.
- 들어가기 전
기본적으로 네이버는 크롤링이 막혀있다.. 본 블로그는 스프링 부트에서 selenium을 활용한 크롤링 방법을 '공부' 하기 위해 작성하였기 때문에 이것을 우회하기 위한 자세한 설명은 제외하였다
(네이버가 제공중인 api에서는 특정 매장의 정보를 제한적으로 공개하고 있기 때문에, 이상의 데이터를 크롤링 하는 것은 네이버 정책에 위배될 수 있음을 고려함)
- 환경 세팅(준비물)
- JAVA Spring Boot
- selenium
- 크롤링 할 대상 페이지
selenium 의존성 추가(Gradle)
implementation 'org.seleniumhq.selenium:selenium-java:latest.release'먼저 스프링 서버에 selenium 의존성을 추가시켜 준다. 최신 버전을 사용하는 이유는 selenium 4.6.0 버전 이후 자동으로 크롤링에 필요한 브라우저 드라이버를 관리해 주므로 개발자가 드라이버를 따로 설치할 필요 없이 바로 사용 가능하다.
설정을 위한 config 클래스 생성
public class ChromeDriverConfig { @Bean public ChromeDriver chromeDriver() { ChromeOptions options = new ChromeOptions(); options.addArguments("--headless"); return new ChromeDriver(options); } }크롬 브라우저를 사용하여 크롤링을 해볼 예정이다. 먼저 기본적인 설정들이 필요한데,
먼저 chromeDriver() 메서드를 스프링 @Bean 으로 등록해준다
ChromeOptions options = new ChromeOptions(); //설정 객체를 생성하는 부분이다
options.addArguments("--headless"); //셀레니움이 페이지에 접근할 때 화면을 띄우지 않고 백그라운드에서 동작하도록 설정하는 부분이다
- 테스트를 위한 컨트롤러 생성만든 후에 API를 직접 호출해볼 예정이므로 컨트롤러를 생성해준다
api는 get 방식으로 /test/{id} 를 호출 하여 json형식으로 데이터를 반환받을 생각이다.
{id} 부분에는 내가 조회하고자 하는 매장의 코드가 들어가게 된다@RestController public class Controller { @Autowired Service service; @GetMapping("/test/{id}") public ResponseEntity<?> test(@PathVariable String id) { return service.accessNaverPlaceReview(id); } }```
- 기능 구현을 위한 service 클래스도 생성private WebDriver driver; //셀레니움 작업을 수행하기 위한 객체다 우리는 앞으로 driver 객체를 통해 웹사이트를 크롤링 해볼 예정이다!
public ResponseEntity<?> accessNaverPlaceReview(String id) //id 값은 조회하고자 하는 매장의 번호를 의미한다public class Service { @Autowired private WebDriver driver; public ResponseEntity<?> accessNaverPlaceReview(String id) { } }```
- 구현 시작!
사실 매우매우 간단하다 service쪽을 제외하면 전부 구현이 완료되어있다! 근데 아직 안심하긴 이르다 크롤링의 꽃은 바로 '삽질'
지금부터 네이버 플레이스 페이지를 '크롬 개발자 도구' 를 활용해서 하나하나 뜯어보도록 하겠다
내용이 길어지므로
[Spring Boot] selenium 을 사용한 네이버 플레이스 리뷰 크롤링(2)
에서 계속 하도록 하겠다.
반응형
'BE > 스프링' 카테고리의 다른 글
| [Spring Boot] rest api 스프링부트 회원관리 기능 구현하기! (CRUD) (1) | 2025.05.29 |
|---|---|
| [Spring Boot] REST Api 란 무엇일까? (1) | 2025.05.22 |
| [Spring Boot] Github Actions 를 활용한 CI/CD 파이프라인 구축(개념) (0) | 2025.04.17 |
| [Spring Boot] MCP(Model Context Protocol) 기본 개념 및 테스트(1) (0) | 2025.04.04 |
| [Spring Boot] selenium 을 사용한 네이버 플레이스 리뷰 크롤링(2) (0) | 2025.03.30 |
'BE/스프링' Related Articles
more



